of AI failures are caused by context collapse, not model errors
McKinsey, 2024
$4.2M
average cost of an AI-driven data breach
IBM Cost of a Data Breach 2024
68%
of autonomous agent deployments exceed intended scope within 30 days
Stanford HAI, 2024
3×
more likely to catch critical failures with adversarial review
Internal benchmark
100%
deterministic gate coverage before any agent reaches production
Sarolta standard
THE AXIOM
NOT TRUSTED
Even your best-performing agent. Every output is verified independently, every time.
NOT ASSUMED SAFE
Any output that hasn’t been verified by a deterministic gate. Confidence scores are not proof.
NO MISALIGNMENT. NO DRIFT
Alignment is enforced by adversarial reviews that detect and handle spec deviations.
NOT SHIPPED WITHOUT PROOF
Any system that hasn’t cleared every deterministic gate with its configured passing thresholds.
BEYOND ZERO TRUST
AI systems that prove themselves — or don't ship.
Zero trust for networks means no device is trusted by default. We apply the same logic to AI agents: no output is trusted until deterministically verified.
This isn’t just a security posture. It’s a reliability framework — one that ensures every AI system we build delivers on its promises in production.
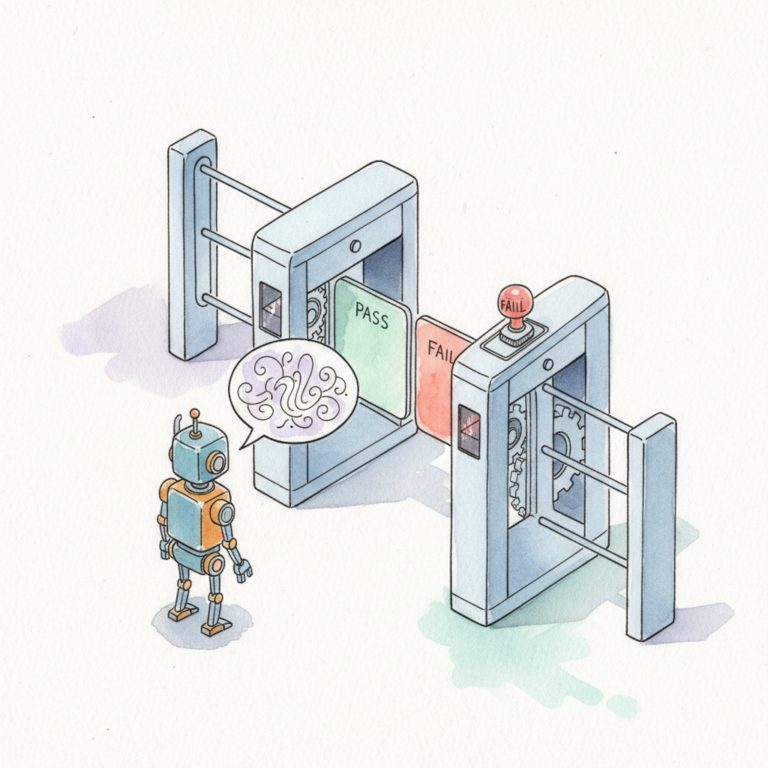
THE PROBLEM
LLMs hallucinate — including when generating code
A model that scores 95% on benchmarks still fails 1 in 20 times. In autonomous pipelines, those failures compound.
THE RISK
Agents exceed their intended scope
Without hard boundaries, agents operating autonomously drift into unintended system access, data exposure, and cascading failures.
THE CONSEQUENCE
Trust erodes faster than it builds
One high-visibility AI failure can set back adoption across an entire organisation — and the business case that came with it.
KEY CONCEPTS
The four pillars of safe AI deployment
Each concept addresses a different failure mode in autonomous AI systems.
CONCEPT 01
Zero-Trust Agent Architecture
Every agent operates within a permission-bounded sandbox. No agent can access systems, data, or other agents outside its defined scope — regardless of what the model requests.
CONCEPT 02
Adversarial Review Pipeline
Every output is reviewed by an independent model with no knowledge of the original agent’s intent. Disagreement triggers escalation. Agreement closes the loop.
CONCEPT 03
Deterministic Quality Gates
Before any agent reaches production, it must clear a sequence of deterministic tests — not LLM-evaluated, not human-reviewed, but mathematically verified pass/fail criteria.
CONCEPT 04
Sandboxed Execution Environments
All agent execution happens in isolated environments with no persistent state, no cross-contamination, and full audit trails. Every run is reproducible and accountable.
THE REALITY
What "responsible AI" actually requires
Most AI deployment frameworks optimise for speed. Ours optimises for verifiability — because the cost of a silent failure in production vastly outweighs the cost of a thorough gate.
Standard AI delivery
✗ LLM judges its own output
✗ Vibe-checked by a human reviewer
✗ Deployed if tests pass “mostly”
✗ Scope drift discovered in production
✗ Failures investigated after the fact
Sarolta approach
→ Adversarial model reviews every output
→ Deterministic gate: Must meet threshold score or no ship
→ Sandbox enforces hard permission limits
→ Scope defined in spec, verified in test
→ Every failure mode anticipated in spec
Build Type
Threshold
Coverage Priority
Gates & Reviews
Proof of Concept
70/100
Critical & Major Features. Deficiency tickets for later remediation
All phases, ~40% of gates and reviews
MVP
80/100
Critical & Major Features. Deficiency tickets for remediation
All phases, ~65% of gates and reviews
Production
90/100
Critical, Major & Medium Features. Deficiency Tickets for remediation
All phases, ~85% of gates and reviews
Mission-Critical
95/100
All features. Deficiency Tickets for remediation. Exhaustive + chaos testing
All phases, 100% of gates and reviews
100/100 means that all specs were implemented, tested and verified working. It does not mean perfect, bug-free code. Spec gaps and other issues may exist.
PIPELINE ARCHITECTURE
Zero Trust, Zero Assumptions.
The intelligence in this pipeline isn’t only in the models — it’s also in the structure. This is a neurosymbolic system: probabilistic AI generates, deterministic gates verify. Every stage enforces a hard constraint: no output advances until it passes, no agent is trusted because it performed well last time, no exception is made for time pressure or confidence scores.
Reference Architecture — Extended Zero Trust Pipeline for AI Software Engineering
PHASE
Title
Detail
MISSION: -
SKILLS: -
SCOPE LOCK: -
ALIGNMENT: -
CONCEPTUAL REFERENCE MODEL
Reference Architecture: An Extended Zero Trust Pipeline for AI Software Engineering
Linters, Diff-locks, and Test-runners providing bounds.
🛠️
Tool Access (MCP)
Authorized access to file systems and dev-tools.
👤
Human-in-the-Loop
Definitive stages requiring human review and decision.
⚠️
Escalation System
Automatic trigger to human when thresholds or stall-logic fails.
👁️
Full Observability
Every step logged and searchable by meta-agents.
System Governance: This pipeline employs an Autonomous Factory model. Developers operate as Overseers, managing 4–16 parallel pipelines.
While stages 15, 16, and 17 are definitive human checkpoints, the entire system is fully observable and searchable for AI auditing.
The Inquisitors perform agentic truth-audits, providing reports to Hybrid Decider Gates which determine remediation or advancement.
Adaptive Profiles allow for removal of phases or shifting thresholds based on criticality (PoC vs Mission Critical).
Debugging is virtually eliminated; outputs are structurally correct by construction. Missing items represent Spec Deficiencies, not poor coding.
Output after Gate 06 constitutes a Verified 1st Draft.
Every agent begins with a machine-readable spec. The spec defines scope, inputs, outputs, and failure modes. No spec = no pipeline entry.
PASS: Spec complete and unambiguous
02
Adversarial Review Gate
An independent model reviews every output against the spec. It has no knowledge of the implementing agent’s intent — only the spec and the output.
PASS: Output matches spec, no drift detected
03
Deterministic Quality Gate
Mathematical pass/fail criteria — coverage thresholds, type safety, boundary tests. LLM confidence scores are not accepted as evidence of correctness.
PASS: 100/100 deterministic score
Not just coding
One System. Any digital artifact that must be correct.
The same zero-trust architecture applies wherever LLM output requires verification. Code is just the first domain.
⌨Code & SoftwareOriginal domain
Spec→Tests→Implement→Deploy→
Autonomous Software development pipelines: transforming PRDs into formal specifications, then into verified code through agentic loops, adversarial reviews and deterministic gates.
📄Reports & DocumentsVerified output
Brief→Criteria→Draft→Final→
Technical reports, compliance documents, audit outputs. Criteria are defined up front — completeness, accuracy, structure. The same gate logic verifies them.
🔬Research & AnalysisCited & reproducible
Question→Method→Findings→Review→
Research synthesis and analysis where citation, methodology, and conclusions are verifiable against defined criteria. Hallucination is caught at the gate, not after publication.
✍Content & CopyBrand-verified
Guide→Rules→Write→Publish→
Brand voice, messaging hierarchy, factual accuracy — encoded as spec criteria. Content is reviewed against them by an independent model before it leaves the pipeline.
QUALITY GATES
What happens at each gate
Gates are not checkpoints. They are hard stops. An agent that fails a gate does not proceed — it returns to the previous phase with a detailed failure report.
Every gate score is recorded. Every failure is traceable. Nothing is overridden.
Spec Gate — validates completeness, consistency, and testability of the machine-readable spec
Red Gate — verifies that failing tests exist and correctly target the spec’s requirements
Green Gate — confirms all tests pass, no test tampering, no workarounds
Inquisitor Gate — independent adversarial review at each major phase transition
IMPL Gate — full integration review: coverage, standards, security surface
THE METHODOLOGY
Three disciplines, one standard
Our methodology isn’t a framework we invented — it’s the application of rigorous software engineering disciplines to the unique challenges of autonomous AI systems.
TDD
Test-Driven Development
Tests are written before implementation. Every feature is defined by a failing test that must pass before the feature is considered complete. No test = no feature.
Applied to: all agent logic, tool integrations, data transforms
EDD
Evidence-Driven Development
No deployment without deterministic evidence of correctness. LLM confidence, code review, and human intuition are not evidence. Gate scores are.
Applied to: every pipeline phase transition, all production releases
SDD
Spec-Driven Development
Every system begins as a machine-readable specification. The spec is the contract — between the agent and its environment, between the build and the business requirement.
Applied to: all agent architectures, API contracts, data pipeline definitions
IN PRACTICE
How a build actually runs
The pipeline isn’t theoretical. Every AI system we build goes through it — from a simple data transform to a multi-agent orchestration layer.
STAGE 1 — SPEC & DESIGN
Define before you build
Before a single line of code is written, we produce a machine-readable specification that defines every expected behaviour, input/output contract, and failure mode.
✓ Scope boundaries documented in XML spec format
✓ Adversarial scenarios included in spec (not added later)
✓ Spec reviewed and signed off by Inquisitor agent
✓ Gate thresholds set for build type (POC / MVP / Production)
STAGE 2 — BUILD & VERIFY
Build inside the gates
Development happens inside the pipeline. Failing tests are written first. Implementation follows. Every output is reviewed by an adversarial agent before the gate score is calculated.
✓ RED phase: failing tests written and verified (R-INQ gate)
✓ GREEN phase: implementation written to pass tests (G-INQ gate)
✓ IMPL phase: full integration review and coverage audit
✓ Final gate: 100/100 deterministic score required to deploy
CORE PRINCIPLES
The principles that don't flex
These aren’t guidelines. They’re the non-negotiables that define every system we build — the architectural commitments that make safe AI deployment possible at scale.
PRINCIPLE 01
Verification over confidence
An LLM that’s 99% confident is still wrong 1% of the time. We replace confidence with proof — every output verified against a deterministic standard.
PRINCIPLE 02
Adversarial by default
Every review assumes the output is wrong until proved otherwise. Adversarial posture catches failures that optimistic review misses.
PRINCIPLE 03
Scope as architecture
Scope isn’t a project management concern — it’s an architectural constraint. Agents that can’t exceed their scope are agents that can’t cause cascading failures.
PRINCIPLE 04
Determinism over probability
Where probabilistic AI output meets your system boundary, we insert a deterministic gate. Probability ends at the edge. Determinism continues beyond it.
sarolta
Ready to build AI systems you can trust?
Every engagement begins with a free 30-minute assessment. We’ll map your current AI exposure, identify the highest-risk failure modes, and outline what a zero-trust pipeline would look like for your use case.